
vue源码分析(十九) 数据响应系统 —— Watcher
# 1. 概述
我们在 vue源码分析(十八) 数据响应系统 —— Observe (opens new window) 一章中有提到过,正是因为 watcher 对表达式的求值,触发了数据属性的 get 拦截器函数,从而收集到了依赖,当数据变化时能够触发响应。 Watcher 观察者实例将对 updateComponent 函数求值,我们知道 updateComponent 函数的执行会间接触发渲染函数(vm.$options.render)的执行,而渲染函数的执行则会触发数据属性的 get 拦截器函数,从而将依赖(观察者)收集,当数据变化时将重新执行 updateComponent 函数,这就完成了重新渲染。同时我们把实例化的观察者对象称为 渲染函数的观察者。
watcher 入口代码如下:
源码目录:scr/core/instance/lifecycle.js
new Watcher(vm, updateComponent, noop, {
before () {
if (vm._isMounted && !vm._isDestroyed) { // 如果已经挂载了,并且没有销毁
callHook(vm, 'beforeUpdate')
}
}
}, true /* isRenderWatcher */)
2
3
4
5
6
7
在分析 Watcher 之前我们还是列举一个案例来说明,代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>深入响应式原理-响应式对象</title>
<script src="../../dist/vue.js"></script>
</head>
<body>
<div id="app"></div>
<script>
new Vue({
el: '#app',
template: `<div> {{ name }} </div>`,
data: {
name: 'robin',
children: {
name: 'child'
}
},
watch: {
'children.name': function(newVal, old) {
console.log(newVal, old)
}
}
})
</script>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 2. Watcher
接下来我们就以渲染函数的观察者对象为例,分析 Watcher 类,Watcher 类定义如下:
源码目录:scr/core/observer/watchere.js
/**
* A watcher parses an expression, collects dependencies,
* and fires callback when the expression value changes.
* This is used for both the $watch() api and directives.
*/
export default class Watcher {
vm: Component;
expression: string;
cb: Function;
id: number;
deep: boolean;
user: boolean;
lazy: boolean;
sync: boolean;
dirty: boolean;
active: boolean;
deps: Array<Dep>;
newDeps: Array<Dep>;
depIds: SimpleSet;
newDepIds: SimpleSet;
before: ?Function;
getter: Function;
value: any;
constructor (
vm: Component, // vm dom
expOrFn: string | Function, // 获取值的函数,或者是更新viwe试图函数
cb: Function, // 回调函数,回调值给回调函数
options?: ?Object, // 参数
isRenderWatcher?: boolean // 是否渲染过得观察者
) {
// 省略...
}
/**
* Evaluate the getter, and re-collect dependencies.
*/
get () {
// 省略...
}
/**
* Add a dependency to this directive.
*/
addDep (dep: Dep) {
// 省略...
}
/**
* Clean up for dependency collection.
*/
cleanupDeps () {
// 省略...
}
/**
* Subscriber interface.
* Will be called when a dependency changes.
*/
update () {
// 省略...
}
/**
* Scheduler job interface.
* Will be called by the scheduler.
*/
run () {
// 省略...
}
/**
* Evaluate the value of the watcher.
* This only gets called for lazy watchers.
*/
/**
* 为计算watcher量身定制的
*/
evaluate () {
// 省略...
}
/**
* Depend on all deps collected by this watcher.
*/
depend () {
// 省略...
}
/**
* Remove self from all dependencies' subscriber list.
*/
teardown () {
// 省略...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
我们先把 Watcher 类精简一下,来看看它的主要属性,通过 Watcher 类的 constructor 方法可以知道在创建 Watcher 实例时可以传递五个参数,分别是:组件实例对象 vm、要观察的表达式 expOrFn、当被观察的表达式的值变化时的回调函数 cb、一些传递给当前观察者对象的选项 options 以及一个布尔值 isRenderWatcher 用来标识该观察者实例是否是渲染函数的观察者。
知道了 Watcher 五个参数的含义,接下来我们看看在首次渲染时 Watcher 的实例化,如下:
源码目录:scr/core/instance/lifecycle.js
new Watcher(vm, updateComponent, noop, {
before () {
if (vm._isMounted && !vm._isDestroyed) { // 如果已经挂载了,并且没有销毁
callHook(vm, 'beforeUpdate')
}
}
}, true /* isRenderWatcher */)
2
3
4
5
6
7
可以看到在创建渲染函数观察者实例对象时传递了全部的五个参数,第一个参数 vm 很显然就是当前组件实例对象;第二个参数 updateComponent 就是被观察的目标,它是一个函数;第三个参数 noop 是一个空函数;第四个参数是一个包含 before 函数的对象,这个对象将作为传递给该观察者的选项;第五个参数为 true,我们知道这个参数标识着该观察者实例对象是否是渲染函数的观察者,很显然上面的代码是在为渲染函数创建观察者对象,所以第五个参数自然为 true。
这里有几个问题需要注意,首先被观察的表达式是一个函数,即 updateComponent 函数,我们知道 Watcher 的原理是通过对“被观测目标”的求值,触发数据属性的 get 拦截器函数从而收集依赖,至于“被观测目标”到底是表达式还是函数或者是其他形式的内容都不重要,重要的是“被观测目标”能否触发数据属性的 get 拦截器函数,很显然函数是具备这个能力的。另外一个我们需要注意的是传递给 Watcher 构造函数的第三个参数 noop 是一个空函数,它什么事情都不会做,有的同学可能会有疑问:“不是说好了当数据变化时重新渲染吗,现在怎么什么都不做了?”,实际上数据的变化不仅仅会执行回调,还会重新对“被观察目标”求值,也就是说 updateComponent 也会被调用,所以不需要通过执行回调去重新渲染。说到这里大家或许又产生了一个疑问:“再次执行 updateComponent 函数难道不会导致再次触发数据属性的 get 拦截器函数导致重复收集依赖吗?”,这是个好问题,不过不用担心,因为 Vue 已经实现了避免收集重复依赖的处理,我们后面会讲到的。
# 2.1 constructor
接下来我们就从 constructor 函数开始,看一下创建渲染函数观察者实例对象的过程,进一步了解一个观察者,如下是 constructor 函数开头的一段代码:
源码目录:scr/core/observer/watchere.js
constructor (
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: ?Object,
isRenderWatcher?: boolean
) {
this.vm = vm
if (isRenderWatcher) {
vm._watcher = this
}
vm._watchers.push(this)
// 省略...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
首先将当前组件实例对象 vm 赋值给该观察者实例的 this.vm 属性,也就是说每一个观察者实例对象都有一个 vm 实例属性,该属性指明了这个观察者是属于哪一个组件的。接着使用 if 条件语句判断 isRenderWatcher 是否为真,前面说过 isRenderWatcher 标识着是否是渲染函数的观察者,只有在 mountComponent 函数中创建渲染函数观察者时这个参数为真,如果 isRenderWatcher 为真那么则会将当前观察者实例赋值给 vm._watcher 属性,也就是说组件实例的 _watcher 属性的值引用着该组件的渲染函数观察者。大家还记得 _watcher 属性是在哪里初始化的吗?是在 initLifecycle 函数中被初始化的,其初始值为 null。在 if 语句块的后面将当前观察者实例对象 push 到 vm._watchers 数组中,也就是说属于该组件实例的观察者都会被添加到该组件实例对象的 vm._watchers 数组中,包括渲染函数的观察者和非渲染函数的观察者。另外组件实例的 vm._watchers 属性是在 initState 函数中初始化的,其初始值是一个空数组。
我们继续往下看,代码如下:
源码目录:scr/core/observer/watchere.js
constructor (
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: ?Object,
isRenderWatcher?: boolean
) {
// 省略...
// options
if (options) {
this.deep = !!options.deep
this.user = !!options.user
this.lazy = !!options.lazy
this.sync = !!options.sync
this.before = options.before
} else {
this.deep = this.user = this.lazy = this.sync = false
}
// 省略...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
上面这段代码是一个 if...else 语句,首先判断 options 参数是否存在,如果存在则执行 if 语句块,如果不存在则执行 else 语句块。if 语句块使用 options 对象中同名属性值的真假来初始化,else 语句块内将当前观察者实例对象的四个属性 this.deep、this.user、this.lazy 以及 this.sync 全部初始化为 false。
通过上面代码我们可以知道实例化 Watcher 时传递的 options 有五个属性,分别为:
options.deep,用来告诉当前观察者实例对象是否是深度观测
我们平时在使用 Vue 的 watch 选项或者 vm.$watch 函数去观测某个数据时,可以通过设置 deep 选项的值为 true 来深度观测该数据。
options.user,用来标识当前观察者实例对象是 开发者定义的 还是 内部定义的
实际上无论是 Vue 的 watch 选项还是 vm.$watch 函数,他们的实现都是通过实例化 Watcher 类完成的,等到我们讲解 Vue 的 watch 选项和 vm.$watch 的具体实现时大家会看到,除了内部定义的观察者(如:渲染函数的观察者、计算属性的观察者等)之外,所有观察者都被认为是开发者定义的,这时 options.user 会自动被设置为 true。
options.lazy,用来标识当前观察者实例对象是否是计算属性的观察者
这里需要明确的是,计算属性的观察者并不是指一个观察某个计算属性变化的观察者,而是指 Vue 内部在实现计算属性这个功能时为计算属性创建的观察者。等到我们讲解计算属性的实现时再详细说明。
options.sync,用来告诉观察者当数据变化时是否同步求值并执行回调
默认情况下当数据变化时不会同步求值并执行回调,而是将需要重新求值并执行回调的观察者放到一个异步队列中,当所有数据的变化结束之后统一求值并执行回调,这么做的好处有很多,我们后面会详细讲解。
options.before,可以理解为Watcher实例的钩子,当数据变化之后,触发更新之前,调用在创建渲染函数的观察者实例对象时传递的before选项。如下代码:
源码目录:scr/core/instance/lifecycle.js
new Watcher(vm, updateComponent, noop, {
before () {
if (vm._isMounted && !vm._isDestroyed) { // 如果已经挂载了,并且没有销毁
callHook(vm, 'beforeUpdate')
}
}
}, true /* isRenderWatcher */)
2
3
4
5
6
7
可以看到当数据变化之后,触发更新之前,如果 vm._isMounted 属性的值为真,则会调用 beforeUpdate 生命周期钩子。
我们继续往下看,代码如下:
源码目录:scr/core/observer/watchere.js
constructor (
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: ?Object,
isRenderWatcher?: boolean
) {
// 省略...
this.cb = cb
this.id = ++uid // uid for batching
this.active = true
this.dirty = this.lazy // for lazy watchers
// 省略...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
这段代码的作用是给当前实例添加 cb、id、active、dirty 属性,并赋值。首先定义了 this.cb 属性,它的值为 cb 回调函数。接着定义了 this.id 属性,它是观察者实例对象的唯一标识。又定义了 this.active 属性,它标识着该观察者实例对象是否是激活状态,默认值为 true 代表激活。最后定义了 this.dirty 属性,该属性的值与 this.lazy 属性的值相同,也就是说只有计算属性的观察者实例对象的 this.dirty 属性的值才会为真,因为计算属性是惰性求值。
我们继续往下看,代码如下:
源码目录:scr/core/observer/watchere.js
constructor (
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: ?Object,
isRenderWatcher?: boolean
) {
// 省略...
this.deps = []
this.newDeps = []
this.depIds = new Set()
this.newDepIds = new Set()
// 省略...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
这四个属性两两一组,this.deps 与 this.depIds 为一组,this.newDeps 与 this.newDepIds 为一组。那么这两组属性的作用是什么呢?其实它们就是用来实现避免收集重复依赖,且移除无用依赖的功能也依赖于它们,后面我们会详细讲解,现在大家注意一下这四个属性的数据结构,其中 this.deps 与 this.newDeps 被初始化为空数组,而 this.depIds 与 this.newDepIds 被初始化为 Set 实例对象。
我们继续往下看,代码如下:
源码目录:scr/core/observer/watchere.js
constructor (
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: ?Object,
isRenderWatcher?: boolean
) {
// 省略...
this.expression = process.env.NODE_ENV !== 'production'
? expOrFn.toString()
: ''
// 省略...
}
2
3
4
5
6
7
8
9
10
11
12
13
这段代码定义了 this.expression 属性,在非生产环境下该属性的值为表达式(expOrFn)的字符串表示,在生产环境下其值为空字符串。所以可想而知 this.expression 属性肯定是在非生产环境下使用的。
我们继续往下看,代码如下:
源码目录:scr/core/observer/watchere.js
constructor (
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: ?Object,
isRenderWatcher?: boolean
) {
// 省略...
if (typeof expOrFn === 'function') {
this.getter = expOrFn
} else {
this.getter = parsePath(expOrFn)
if (!this.getter) {
this.getter = noop
process.env.NODE_ENV !== 'production' && warn(
`Failed watching path: "${expOrFn}" ` +
'Watcher only accepts simple dot-delimited paths. ' +
'For full control, use a function instead.',
vm
)
}
}
// 省略...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
这段代码检测了 expOrFn 的类型,如果 expOrFn 是函数,那么直接使用 expOrFn 作为 this.getter 属性的值。如果 expOrFn 不是函数,那么将 expOrFn 传给 parsePath 函数,并以 parsePath 函数的返回值作为 this.getter 属性的值。
观察者实例对象的 this.getter 函数终将会是一个函数,如果不是函数,此时只有一种可能,那就是 parsePath 函数在解析表达式的时候失败了,那么这时在非生产环境会打印警告信息,告诉开发者:Watcher 只接受简单的点(.)分隔路径,如果你要用全部的 js 语法特性直接观察一个函数即可。
说明:关于 parsePath 函数我们在下一小节详细分析。
我们继续看constructor 中的最后一段代码,代码如下:
源码目录:scr/core/observer/watchere.js
constructor (
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: ?Object,
isRenderWatcher?: boolean
) {
// 省略...
this.value = this.lazy
? undefined
: this.get()
}
2
3
4
5
6
7
8
9
10
11
12
通过这段代码我们可以发现,计算属性的观察者和其他观察者实例对象的处理方式是不同的,对于计算属性的观察者我们会在讲解计算属性时详细说明。除计算属性的观察者之外的所有观察者实例对象都将执行如上代码的 else 分支语句,即调用 this.get() 方法。
# 2.2 parsePath
我们先来看一下 parsePath 函数定义,源码如下:
源码目录: src/core/util/lang.js
/**
* unicode letters used for parsing html tags, component names and property paths.
* using https://www.w3.org/TR/html53/semantics-scripting.html#potentialcustomelementname
* skipping \u10000-\uEFFFF due to it freezing up PhantomJS
*/
// unicode代表:·À-ÖØ-öø-ͽͿ--‿-⁀⁰-Ⰰ-、-豈-﷏ﷰ-�
export const unicodeRegExp = /a-zA-Z\u00B7\u00C0-\u00D6\u00D8-\u00F6\u00F8-\u037D\u037F-\u1FFF\u200C-\u200D\u203F-\u2040\u2070-\u218F\u2C00-\u2FEF\u3001-\uD7FF\uF900-\uFDCF\uFDF0-\uFFFD/
/**
* Parse simple path.
*/
const bailRE = new RegExp(`[^${unicodeRegExp.source}.$_\\d]`)
export function parsePath (path: string): any {
if (bailRE.test(path)) {
return
}
const segments = path.split('.')
return function (obj) { //返回一个函数,参数是一个对象
for (let i = 0; i < segments.length; i++) {
if (!obj) return
obj = obj[segments[i]]
}
return obj
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
首先我们需要知道 parsePath 函数接收的参数是什么,如下是平时我们使用 $watch 函数的例子:
// 函数
const expOrFn = function () {
return this.obj.a
}
this.$watch(expOrFn, function () { /* 回调 */ })
// 表达式
const expOrFn = 'obj.a'
this.$watch(expOrFn, function () { /* 回调 */ })
2
3
4
5
6
7
8
9
以上两种用法实际上是等价的,当 expOrFn 不是函数时,比如上例中的 'obj.a' 是一个字符串,这时便会将该字符串传递给 parsePath 函数,其实我们可以看到 parsePath 函数的返回值是另一个函数,那么返回的新函数的作用是什么呢?很显然其作用是触发 'obj.a' 的 get 拦截器函数,同时新函数会将 'obj.a' 的值返回。
接下来我们具体看一下 parsePath 函数的具体实现,首先来看一下在 parsePath 函数之前定义的 bailRE 正则,这个正则将匹配一个位置,该位置满足三个条件:
- 不是
unicodeRegExp中的字符,也就是说这个位置不能是 字母 或 数字 或 下划线 或 一些特殊符号 - 不是字符
. - 不是字符
$
举几个例子如 obj~a、obj/a、obj*a、obj+a 等,这些字符串中的 ~、/、* 以及 + 字符都能成功匹配正则 bailRE,这时 parsePath 函数将返回 undefined,也就是解析失败。实际上这些字符串在 javascript 中不是一个合法的访问对象属性的语法,按照 bailRE 正则只有如下这几种形式的字符串才能解析成功:obj.a、this.$watch 等,看到这里你也应该知道为什么 bailRE 正则中包含字符 . 和 $。
在 parsePath 首先判断如果参数 path 不满足正则 bailRE,则直接返回,如果满足,则继续执行后面的代码。接下来定义 segments 常量,它的值是通过字符 . 分割 path 字符串产生的数组,随后 parsePath 函数将返回值一个函数,该函数的作用是遍历 segments 数组循环访问 path 指定的属性值。这样就触发了数据属性的 get 拦截器函数。但要注意 parsePath 返回的新函数将作为 this.getter 的值,只有当 this.getter 被调用的时候,这个函数才会执行。
# 2.3 收集依赖
get 的作用就只 求值,求值的目的有两个,第一个是能够触发访问器属性的 get 拦截器函数,第二个是能够获得被观察目标的值。而且能够触发访问器属性的 get 拦截器函数是依赖被收集的关键,下面我们具体查看一下 this.get() 方法的内容:
源码目录:scr/core/observer/watchere.js
/**
* Evaluate the getter, and re-collect dependencies.
*/
get () {
pushTarget(this)
let value
const vm = this.vm
try {
value = this.getter.call(vm, vm)
} catch (e) {
if (this.user) {
handleError(e, vm, `getter for watcher "${this.expression}"`)
} else {
throw e
}
} finally {
// "touch" every property so they are all tracked as
// dependencies for deep watching
if (this.deep) {
traverse(value)
}
popTarget()
this.cleanupDeps()
}
return value
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
get 首先调用 pushTarget 函数,参数为当前 Watcher 实例,我们先来看看 pushTarget 的定义:
源码目录:scr/core/observer/dep.js
// The current target watcher being evaluated.
// This is globally unique because only one watcher
// can be evaluated at a time.
Dep.target = null
const targetStack = []
export function pushTarget (target: ?Watcher) {
targetStack.push(target)
Dep.target = target
}
2
3
4
5
6
7
8
9
10
11
在上一章节中我们讲过每个响应式数据的属性都通过闭包引用着一个用来收集属于自身依赖的“筐”,实际上那个“筐”就是 Dep 类的实例对象。在上面这段代码中我们可以看到 Dep 类拥有一个静态属性,即 Dep.target 属性,该属性的初始值为 null,其实 pushTarget 函数的作用就是用来为 Dep.target 属性赋值的,pushTarget 函数会将接收到的参数赋值给 Dep.target 属性,我们知道传递给 pushTarget 函数的参数就是调用该函数的观察者对象,所以 Dep.target 保存着一个观察者对象,其实这个观察者对象就是即将要收集的目标。
我们回到 get 继续往下看,接下来是定义一个 value 变量,该变量的值为 this.getter 函数的返回值,我们知道观察者对象的 this.getter 属性是一个函数,这个函数的执行就意味着对被观察目标的求值,并将得到的值赋值给 value 变量,而且我们可以看到 this.get 方法的最后将 value 返回。
以我们本章的案例为例,即渲染函数的观察者为例,生成的 render 函数为:
function anonymous() {
with(this){
return _c(
'div',
[_v(" "+_s(name)+" ")]
)
}
}
2
3
4
5
6
7
8
最终生成的渲染函数的执行会读取数据属性 name 的值,这将会触发 name 属性的 get 拦截器函数,在上一章我们分析过数据的响应式是通过 defineReactive 来实现的,源码如下:
源码目录:scr/core/observer/index.js
export function defineReactive (
obj: Object,
key: string,
val: any,
customSetter?: ?Function,
shallow?: boolean
) {
// 省略...
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
// 当obj的某个属性被访问的时候,就会调用getter方法
const value = getter ? getter.call(obj) : val
// 当Dep.target不为空时,调用dep.depend 和 childOb.dep.depend方法做依赖收集
if (Dep.target) {
// 通过dep对象, 收集依赖关系
dep.depend()
if (childOb) {
childOb.dep.depend()
// 如果访问的是一个数组, 则会遍历这个数组, 收集数组元素的依赖
if (Array.isArray(value)) {
dependArray(value)
}
}
}
return value
},
// 省略...
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
这段代码是数据属性的 get 拦截器函数,由于渲染函数读取了 name 属性的值,所以 name 属性的 get 拦截器函数将被执行,上面代码中,首先判断了 Dep.target 是否存在,如果存在则调用 dep.depend 方法收集依赖。这就是为什么 pushTarget 函数要在调用 this.getter 函数之前被调用的原因。既然 dep.depend 方法被执行,那么我们就找到 dep.depend 方法,代码如下:
源码目录:scr/core/observer/dep.js
let uid = 0
/**
* A dep is an observable that can have multiple
* directives subscribing to it.
*/
export default class Dep {
// 省略...
// 收集依赖关系
depend () {
// 把当前Dep对象实例添加到当前正在计算的Watcher的依赖中
if (Dep.target) {
Dep.target.addDep(this)
}
}
// 省略...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
在 dep.depend 方法内部又判断了一次 Dep.target 是否有值,有的同学可能会有疑问,这不是多此一举吗?其实这么做并不多余,因为 dep.depend 方法除了在属性的 get 拦截器函数内被调用之外还在其他地方被调用了,这时候就需要对 Dep.target 做判断,至于在哪里调用的我们后面会讲到。另外我们发现在 depend 方法内部其实并没有真正的执行收集依赖的动作,而是调用了观察者实例对象的 addDep 方法:Dep.target.addDep(this),并以当前 Dep 实例对象作为参数。
我们再来看看 Watcher 的 addDep 方法的定义,如下:
源码目录:scr/core/observer/watchere.js
/**
* Add a dependency to this directive.
*/
addDep (dep: Dep) {
const id = dep.id
if (!this.newDepIds.has(id)) {
this.newDepIds.add(id)
this.newDeps.push(dep)
if (!this.depIds.has(id)) {
dep.addSub(this)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
可以看到 addDep 方法接收一个参数,这个参数是一个 Dep 对象,在 addDep 方法内部首先定义了常量 id,它的值是 Dep 实例对象的唯一 id 值。接着是一段 if 语句块,该 if 语句块的代码很关键,因为它的作用就是用来 避免收集重复依赖 的,既然是用来避免收集重复的依赖,那么就不得不用到我们前面提到过的两组属性,即 newDepIds、newDeps 以及 depIds、deps。
为了让大家更好地理解,我们思考一下可不可以把 addDep 方法修改成如下这样:
addDep (dep: Dep) {
dep.addSub(this)
}
2
3
首先解释一下 dep.addSub 方法,它的源码如下:
源码目录:scr/core/observer/dep.js
addSub (sub: Watcher) {
this.subs.push(sub)
}
2
3
addSub 方法接收观察者对象作为参数,并将接收到的观察者添加到 Dep 实例对象的 subs 数组中,其实 addSub 方法才是真正用来收集观察者的方法,并且收集到的观察者都会被添加到 subs 数组中存起来。
了解了 addSub 方法之后,我们再回到如下这段代码:
addDep (dep: Dep) {
dep.addSub(this)
}
2
3
我们修改了 addDep 方法,直接在 addDep 方法内调用 dep.addSub 方法,并将当前观察者对象作为参数传递。这不是很好吗?难道有什么问题吗?当然有问题,假如我们有如下模板:
<div> {{ name }} {{ name }}</div>
这段模板的不同之处在于我们使用了两次 name 数据,那么相应的渲染函数也将变为如下这样:
function anonymous() {
with(this){
return _c(
'div',
[_v(" "+_s(name)+_s(name)+" ")]
)
}
}
2
3
4
5
6
7
8
可以看到,渲染函数的执行将读取两次数据对象 name 属性的值,这必然会触发两次 name 属性的 get 拦截器函数,同样的道理,dep.depend 也将被触发两次,最后导致 dep.addSub 方法被执行了两次,且参数一模一样,这样就产生了同一个观察者被收集多次的问题。所以我们不能像如上那样修改 addDep 函数的代码。
我们再回到 addDep,在 addDep 内部并不是直接调用 dep.addSub 收集观察者,而是先根据 dep.id 属性检测该 Dep 实例对象是否已经存在于 newDepIds 中,如果存在那么说明已经收集过依赖了,什么都不会做。如果不存在才会继续执行 if 语句块的代码,同时将 dep.id 属性和 Dep 实例对象本身分别添加到 newDepIds 和 newDeps 属性中,这样无论一个数据属性被读取了多少次,对于同一个观察者它只会收集一次。
这里的判断条件 !this.depIds.has(id) 是什么意思呢?我们知道 newDepIds 属性用来避免在 一次求值 的过程中收集重复的依赖,其实 depIds 属性是用来在 多次求值 中避免收集重复依赖的。什么是多次求值,其实所谓多次求值是指当数据变化时重新求值的过程。大家可能会疑惑,难道重新求值的时候不能用 newDepIds 属性来避免收集重复的依赖吗?不能,原因在于每一次求值之后 newDepIds 属性都会被清空,也就是说每次重新求值的时候对于观察者实例对象来讲 newDepIds 属性始终是全新的。虽然每次求值之后会清空 newDepIds 属性的值,但在清空之前会把 newDepIds 属性的值以及 newDeps 属性的值赋值给 depIds 属性和 deps 属性,这样重新求值的时候 depIds 属性和 deps 属性将会保存着上一次求值中 newDepIds 属性以及 newDeps 属性的值。
我们继续回到 get() 方法往下看,可以看到在 finally 语句块内调用了观察者对象的 cleanupDeps 方法,这个方法的作用正如我们前面所说的那样,每次求值完毕后都会使用 depIds 属性和 deps 属性保存 newDepIds 属性和 newDeps 属性的值,然后再清空 newDepIds 属性和 newDeps 属性的值。
我们再来看看 Watcher 的 cleanupDeps 方法的定义,如下:
源码目录:scr/core/observer/watchere.js
/**
* Clean up for dependency collection.
*/
cleanupDeps () {
let i = this.deps.length
while (i--) {
const dep = this.deps[i]
if (!this.newDepIds.has(dep.id)) {
dep.removeSub(this) //清除 sub
}
}
let tmp = this.depIds // 获取depids
this.depIds = this.newDepIds // 获取新的depids
this.newDepIds = tmp // 旧的覆盖新的
this.newDepIds.clear() //清空对象
// 互换值
tmp = this.deps
this.deps = this.newDeps
this.newDeps = tmp
this.newDeps.length = 0
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
在 cleanupDeps 方法内部,首先是一个 while 循环,我们暂且不关心这个循环的作用,我们看循环下面的代码,这段代码是典型的引用类型变量交换值的过程,最终的结果就是 newDepIds 属性和 newDeps 属性被清空,并且在被清空之前把值分别赋给了 depIds 属性和 deps 属性,这两个属性将会用在下一次求值时避免依赖的重复收集。
现在我们可以做几点总结:
- 1、
newDepIds属性用来在一次求值中避免收集重复的观察者 - 2、每次求值并收集观察者完成之后会清空
newDepIds和newDeps这两个属性的值,并且在被清空之前把值分别赋给了depIds属性和deps属性 - 3、
depIds属性用来避免重复求值时收集重复的观察者
通过以上三点内容我们可以总结出一个结论,即 newDepIds 和 newDeps 这两个属性的值所存储的总是当次求值所收集到的 Dep 实例对象,而 depIds 和 deps 这两个属性的值所存储的总是上一次求值过程中所收集到的 Dep 实例对象。
除了以上三点之外,其实 deps 属性还能够用来移除废弃的观察者,cleanupDeps 方法中开头的那段 while 循环就是用来实现这个功能的。 while 循环就是对 deps 数组进行遍历,也就是对上一次求值所收集到的 Dep 对象进行遍历,然后在循环内部检查上一次求值所收集到的 Dep 实例对象是否存在于当前这次求值所收集到的 Dep 实例对象中,如果不存在则说明该 Dep 实例对象已经和该观察者不存在依赖关系了,这时就会调用 dep.removeSub(this) 方法并以该观察者实例对象作为参数传递,从而将该观察者对象从 Dep 实例对象中移除。
我们再来看看 Dep 类的 removeSub 方法的定义,如下:
源码目录:scr/core/observer/dep.js
removeSub (sub: Watcher) {
remove(this.subs, sub)
}
2
3
removeSub 方法接收一个要被移除的观察者作为参数,然后使用 remove 工具函数,将该观察者从 this.subs 数组中移除。
说明:关于 traverse 我们将在深度观测的小节具体分析。
# 2.4 触发依赖
在上一小节中我们提到了,每次求值并收集完观察者之后,会将当次求值所收集到的观察者保存到另外一组属性中,即 depIds 和 deps,并将存有当次求值所收集到的观察者的属性清空,即清空 newDepIds 和 newDeps。我们当时也说过了,这么做的目的是为了对比当次求值与上一次求值所收集到的观察者的变化情况,并做出合理的矫正工作,比如移除那些已经没有关联关系的观察者等。本节我们将以数据属性的变化为切入点,讲解重新求值的过程。
在们当前案例中模板将会被编译成渲染函数,接着创建一个渲染函数的观察者,从而对渲染函数求值,在求值的过程中会触发数据对象 name 属性的 get 拦截器函数,进而将该观察者收集到 name 属性通过闭包引用的“筐”中,即收集到 Dep 实例对象中。这个 Dep 实例对象是属于 name 属性自身所拥有的,这样当我们尝试修改数据对象 name 属性的值时就会触发 name 属性的 set 拦截器函数,这样就有机会调用 Dep 实例对象的 notify 方法,从而触发了响应。
在上一章我们分析过数据的响应式是通过 defineReactive 来实现的,当属性值变化时确实通过 set 拦截器函数调用了 Dep 实例对象的 notify 方法,这个方法就是用来通知变化的,源码如下:
源码目录:scr/core/observer/index.js
export function defineReactive (
obj: Object,
key: string,
val: any,
customSetter?: ?Function,
shallow?: boolean
) {
// 省略...
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
set: function reactiveSetter (newVal) {
// 当改变obj的属性是,就会调用setter方法。这是就会调用dep.notify方法进行通知
const value = getter ? getter.call(obj) : val
/* eslint-disable no-self-compare */
// 新旧值相等 或 新旧值都等于NaN时
if (newVal === value || (newVal !== newVal && value !== value)) {
return
}
/* eslint-enable no-self-compare */
if (process.env.NODE_ENV !== 'production' && customSetter) {
customSetter()
}
// #7981: for accessor properties without setter
if (getter && !setter) return
if (setter) {
setter.call(obj, newVal)
} else {
val = newVal
}
// 对新值进行观测
childOb = !shallow && observe(newVal)
// 当响应式属性发生修改时,通过dep对象通知依赖的vue实例进行更新
dep.notify()
}
// 省略...
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
我们再来看看 Dep 类的 notify 方法的定义,如下:
源码目录:scr/core/observer/dep.js
export default class Dep {
static target: ?Watcher;
id: number;
subs: Array<Watcher>;
constructor () {
// dep对象的id
this.id = uid++
// 数组,用来存储依赖响应式属性的Observer
this.subs = []
}
// 省略...
notify () {
// stabilize the subscriber list first
const subs = this.subs.slice()
if (process.env.NODE_ENV !== 'production' && !config.async) {
// subs aren't sorted in scheduler if not running async
// we need to sort them now to make sure they fire in correct
// order
subs.sort((a, b) => a.id - b.id)
}
// 遍历所有的订阅Watcher,然后调用他们的update方法
for (let i = 0, l = subs.length; i < l; i++) {
subs[i].update()
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
notify 首先通过 slice 方法获取到所有的观察者对象并保存在 subs 变量中,接下来的 if 语句的作用是判断在同步执行的观察者时,在执行观察者对象的 update 更新方法之前就对观察者进行排序,从而保证正确的更新顺序。最后遍历所有的观察者对象,逐个调用观察者对象的 update 方法,这就是触发响应的实现机制。
接下来我们回到 watcher 类,再来看看 update 方法的定义,如下:
源码目录:scr/core/observer/watcher.js
/**
* Subscriber interface.
* Will be called when a dependency changes.
*/
update () {
/* istanbul ignore else */
if (this.lazy) {
this.dirty = true
} else if (this.sync) {
this.run()
} else {
queueWatcher(this)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
在 update 方法中代码被拆分成了三部分,即 if...else if...else 语句块。首先 if 语句块的代码会在判断条件 this.lazy 为真的情况下执行,我们说过 this.lazy 属性是用来判断该观察者是不是计算属性的观察者。也就是说渲染函数的观察者肯定是不会执行 if 语句块中的代码的,此时会继续判断 else...if 语句的条件 this.sync 是否为真,我们知道 this.sync 属性的值就是创建观察者实例对象时传递的第三个选项参数中的 sync 属性的值,这个值的真假代表了当变化发生时是否同步更新变化。对于渲染函数的观察者来讲,它并不是同步更新变化的,而是将变化放到一个异步更新队列中,也就是 else 语句块中代码所做的事情,即 queueWatcher 会将当前观察者对象放到一个异步更新队列,这个队列会在调用栈被清空之后按照一定的顺序执行。无论是同步更新变化还是将更新变化的操作放到异步更新队列,真正的更新变化操作都是通过调用观察者实例对象的 run 方法完成的。
说明:关于异步更新队列和计算属性我们将在后面小节具体分析。
我们再来看看 Dep 类的 run 方法的定义,如下:
源码目录:scr/core/observer/dep.js
/**
* Scheduler job interface.
* Will be called by the scheduler.
*/
run () {
if (this.active) {
const value = this.get() // 获取新值
if (
value !== this.value || // 新值和旧值不相等
// Deep watchers and watchers on Object/Arrays should fire even
// when the value is the same, because the value may
// have mutated.
isObject(value) || // 新值是对象
this.deep // deep为true
) {
// set new value
const oldValue = this.value
this.value = value
if (this.user) { // 如果是个用户 watcher
try {
// 执行这个回调函数 vm作为上下文 参数1为新值 参数2为旧值,
// 也就是最后我们自己定义的function(newval,val){ console.log(newval,val) }函数
this.cb.call(this.vm, value, oldValue)
} catch (e) {
handleError(e, this.vm, `callback for watcher "${this.expression}"`)
}
} else {
this.cb.call(this.vm, value, oldValue)
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
run 方法首先判断了当前观察者实例的 this.active 属性是否为真,其中 this.active 属性用来标识一个观察者是否处于激活状态,或者可用状态。如果观察者处于激活状态那么 this.active 的值为真,则会执行 if 语句块。if 语句块首先调用this.get 方法,这意味着重新求值。对于渲染函数的观察者来讲,重新求值其实等价于重新执行渲染函数,最终结果就是重新生成了虚拟 DOM 并更新真实 DOM,这样就完成了重新渲染的过程。
在重新调用 this.get 方法之后是一个 if 语句块,实际上对于渲染函数的观察者来讲并不会执行这个 if 语句块,因为 this.get 方法的返回值其实就等价于 updateComponent 函数的返回值,这个值将永远都是 undefined。实际上 if 语句块内的代码是为非渲染函数类型的观察者准备的,它用来对比新旧两次求值的结果,当值不相等的时候会调用通过参数传递进来的回调。
首先对比新值 value 和旧值 this.value 是否相等,只有在不相等的情况下才需要执行回调,或者检测第二个条件是否成立,即 isObject(value),判断新值的类型是否是对象,如果是对象的话即使值不变也需要执行回调,注意这里的“不变”指的是引用不变。
如果判断条件为真则执行 if 语句块,即执行观察者的回调函数。首先定义了 oldValue 常量,它的值是旧值,紧接着使用新值更新了 this.value 的值。
在调用回调函数的时候,如果观察者对象的 this.user 为真意味着这个观察者是开发者定义的,所谓开发者定义的是指那些通过 watch 选项或 $watch 函数定义的观察者,这些观察者的特点是回调函数是由开发者编写的,所以这些回调函数在执行的过程中其行为是不可预知的,很可能出现错误,这时候将其放到一个 try...catch 语句块中,这样当错误发生时我们就能够给开发者一个友好的提示。并且我们注意到在提示信息中包含了 this.expression 属性,我们前面说过该属性是被观察目标(expOrFn)的字符串表示,这样开发者就能清楚的知道是哪里发生了错误。
最后调用回调函数 this.cb ,当变化发生时会触发,但是对于渲染函数的观察者来讲,this.cb 属性的值为 noop,即什么都不做。我们可以看到不管是 if 语句块还是 else 语句块都会执行回调函数,即将回调函数的作用域修改为当前 Vue 组件对象,然后传递了两个参数,分别是新值和旧值。
# 2.5 异步更新
# 2.5.1 JS运行机制
为了方便大家理解,我先简单介绍 一下JS 的运行机制 (opens new window)。
JS 执行是单线程的,它是基于事件循环的。事件循环大致分为以下几个步骤:
- 所有同步任务都在主线程上执行,形成一个执行栈
(execution context stack)。 - 主线程之外,还存在一个"任务队列"
(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。 - 一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
- 主线程不断重复上面的第三步。
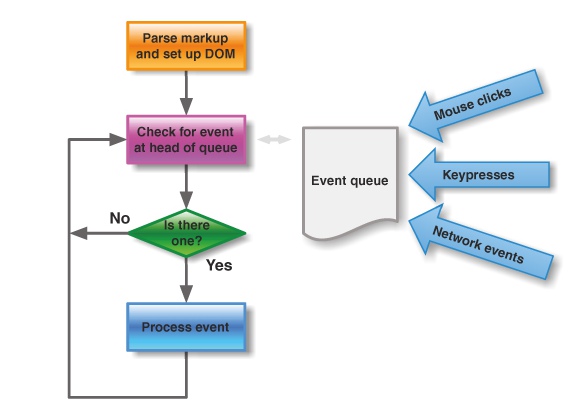
主线程的执行过程就是一个 tick,而所有的异步结果都是通过 “任务队列” 来调度被调度。 消息队列中存放的是一个个的任务(task)。 规范中规定 task 分为两大类,分别是 macro task 和 micro task,并且每个 macro task 结束后,都要清空所有的 micro task。
关于 macro task 和 micro task 的概念参考这里 (opens new window),简单通过一段代码演示他们的执行顺序:
for (macroTask of macroTaskQueue) {
// 1. Handle current MACRO-TASK
handleMacroTask();
// 2. Handle all MICRO-TASK
for (microTask of microTaskQueue) {
handleMicroTask(microTask);
}
}
2
3
4
5
6
7
8
在浏览器环境中,常⻅的 macro task 有 setTimeout、MessageChannel、postMessage、setImmediate;常 ⻅的 micro task 有 MutationObsever 和 Promise.then。
我们对 JS 的运行机制讲解清楚,下面我们我们再来看看同步更新和异步更新。
# 2.5.2 同步更新
我们以本章的案例为基础,稍微修改一下我们案例,如下:
new Vue({
el: '#app',
template: `<div> {{ name }} </div>`,
data: {
name: 'robin',
children: {
name: 'child',
age: 18
}
},
mounted () {
this.name = 'hcy'
}
})
2
3
4
5
6
7
8
9
10
11
12
13
14
我们在模板中使用了数据对象的 name 属性,这意味着 name 属性将会收集渲染函数的观察者作为依赖,接着我们在 mounted 钩子中修改了 name 属性的值,这样就会触发响应:渲染函数的观察者会重新求值,完成重渲染。
这个过程从属性值的变化到完成重新渲染,这是一个同步更新的过程,大家思考一下“同步更新”会导致什么问题?很显然这会导致每次属性值的变化都会引发一次重新渲染,假设我们要修改两个属性的值,那么同步更新将导致两次的重渲染。
有时候这是致命的缺陷,想象一下复杂业务场景,你可能会同时修改很多属性的值,如果每次属性值的变化都要重新渲染,就会导致严重的性能问题,而异步更新队列就是用来解决这个问题的。
# 2.5.3 异步更新
与同步更新的不同之处在于,每次修改属性的值之后并没有立即重新求值,而是将需要执行更新操作的观察者放入一个队列中。当我们修改 name 属性值时,由于 name 属性收集了渲染函数的观察者作为依赖,所以此时渲染函数的观察者 会被添加到队列中,接着我们修改了 age 属性的值,由于 age 属性也收集了渲染函数的观察者作为依赖,所以此时也会尝试将渲染函数的观察者添加到队列中,但是由于渲染函数的观察者已经存在于队列中了,所以并不会重复添加,这样队列中将只会存在一个渲染函数的观察者。当所有的突变完成之后,再一次性的执行队列中所有观察者的更新方法,同时清空队列,这样就达到了优化的目的。
接下来我们就从具体代码入手,看一看其具体实现,我们知道当修改一个属性的值时,会通过执行该属性所收集的所有观察者对象的 update 方法进行更新,那么我们就找到观察者对象的 update 方法,如下:
源码目录:scr/core/observer/watcher.js
/**
* Subscriber interface.
* Will be called when a dependency changes.
*/
update () {
/* istanbul ignore else */
if (this.lazy) {
this.dirty = true
} else if (this.sync) {
this.run()
} else {
queueWatcher(this)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
在 update 如果没有指定这个观察者是同步更新(this.sync 为真),那么这个观察者的更新机制就是异步的,这时当调用观察者对象的 update 方法时,在 update 方法内部会调用 queueWatcher 函数,并将当前观察者对象作为参数传递,queueWatcher 函数的作用就是它将观察者放到一个队列中等待所有突变完成之后统一执行更新。
我们再来看看 queueWatcher 方法的定义,如下:
源码目录:src/core/observer/scheduler.js
const queue: Array<Watcher> = []
let has: { [key: number]: ?true } = {}
let waiting = false
let flushing = false
/**
* Push a watcher into the watcher queue.
* Jobs with duplicate IDs will be skipped unless it's
* pushed when the queue is being flushed.
*/
export function queueWatcher (watcher: Watcher) {
const id = watcher.id
if (has[id] == null) {
has[id] = true
if (!flushing) {
queue.push(watcher)
} else {
// if already flushing, splice the watcher based on its id
// if already past its id, it will be run next immediately.
let i = queue.length - 1
while (i > index && queue[i].id > watcher.id) {
i--
}
queue.splice(i + 1, 0, watcher)
}
// queue the flush
if (!waiting) {
waiting = true
if (process.env.NODE_ENV !== 'production' && !config.async) {
flushSchedulerQueue()
return
}
nextTick(flushSchedulerQueue)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
queueWatcher 函数接收观察者对象作为参数,首先定义了 id 常量,它的值是观察者对象的唯一 id,然后执行 if 判断语句。其中变量 has 定义在 scheduler.js 文件头部,它是一个空对象。当 queueWatcher 函数被调用之后,会尝试将该观察者放入队列中,并将该观察者的 id 值登记到 has 对象上作为 has 对象的属性同时将该属性值设置为 true。该 if 语句以及变量 has 的作用就是用来避免将相同的观察者重复入队的。
在该 if 语句块内执行了真正的入队操作,在入队之前有一个对变量 flushing 的判断,它的初始值是 false,flushing 变量是一个标志,我们知道放入队列 queue 中的所有观察者将会在突变完成之后统一执行更新,当更新开始时会将 flushing 变量的值设置为 true,代表着此时正在执行更新,所以根据判断条件 if (!flushing) 可知只有当队列没有执行更新时才会简单地将观察者追加到队列的尾部,即 queue.push(watcher),这里需要强调的是在队列执行更新的过程中还会有观察者入队的操作,典型的例子就是计算属性,比如队列执行更新时经常会执行渲染函数观察者的更新,渲染函数中很可能有计算属性的存在,由于计算属性在实现方式上与普通响应式属性有所不同,所以当触发计算属性的 get 拦截器函数时会有观察者入队的行为,这个时候我们需要特殊处理,也就是 else 分支的代码。
当变量 flushing 为真时,说明队列正在执行更新,这时如果有观察者入队则会执行 else 分支中的代码,这段代码的作用是为了保证观察者的执行顺序,现在大家只需要知道观察者会被放入 queue 队列中即可,我们后面会详细讨论。
接下来又是一个 if 语句,其中变量 waiting 同样是一个标志,初始值为 false,在 if 语句块内先将 waiting 的值设置为 true,这意味着无论调用多少次 queueWatcher 函数,该 if 语句块的代码只会执行一次。接着调用 nextTick 并以 flushSchedulerQueue 函数作为参数,其中 flushSchedulerQueue 函数的作用之一就是用来将队列中的观察者统一执行更新的。对于 nextTick 相信大家已经很熟悉了,其实最好理解的方式就是把 nextTick 看做 setTimeout(fn, 0)。
# 2.5.4 nextTick
vm.$nextTick 方法是在 renderMixin 函数中挂载到 Vue 原型上的,可以看到 $nextTick 函数体只有一句话即调用 nextTick 函数,这说明 $nextTick 确实是对 nextTick 函数的简单包装。
源码目录:src/core/instance/render.js
export function renderMixin (Vue: Class<Component>) {
// 省略...
// 给 Vue 原型上添加 $nextTick API
Vue.prototype.$nextTick = function (fn: Function) {
return nextTick(fn, this)
}
// 省略...
}
2
3
4
5
6
7
8
9
10
同理,Vue.nextTick 方法是在 initGlobalAPI 函数中挂载到 Vue 构造函数上的,可以看到 nextTick 是 nextTick 函数的引用。
源码目录:src/core/global-api/index.js
export function initGlobalAPI (Vue: GlobalAPI) {
// 省略...
Vue.nextTick = nextTick
// 省略...
}
2
3
4
5
我们知道任务队列并非只有一个队列,在 node 中更为复杂,但总的来说我们可以将其分为 microtask 和 (macro)task,并且这两个队列的行为还要依据不同浏览器的具体实现去讨论,这里我们只讨论被广泛认同和接受的队列执行行为。当调用栈空闲后每次事件循环只会从 (macro)task 中读取一个任务并执行,而在同一次事件循环内会将 microtask 队列中所有的任务全部执行完毕,且要先于 (macro)task。另外 (macro)task 中两个不同的任务之间可能穿插着UI的重渲染,那么我们只需要在 microtask 中把所有在UI重渲染之前需要更新的数据全部更新,这样只需要一次重渲染就能得到最新的DOM了。恰好 Vue 是一个数据驱动的框架,如果能在UI重渲染之前更新所有数据状态,这对性能的提升是一个很大的帮助,所有要优先选用 microtask 去更新数据状态而不是 (macro)task,这就是为什么不使用 setTimeout 的原因,因为 setTimeout 会将回调放到 (macro)task 队列中而不是 microtask 队列,所以理论上最优的选择是使用 Promise,当浏览器不支持 Promise 时再降级为 setTimeout。
下面我们看看,nextTick 的实现,如下:
源码目录:src/core/util/next-tick.js
export let isUsingMicroTask = false
// Here we have async deferring wrappers using microtasks.
// In 2.5 we used (macro) tasks (in combination with microtasks).
// However, it has subtle problems when state is changed right before repaint
// (e.g. #6813, out-in transitions).
// Also, using (macro) tasks in event handler would cause some weird behaviors
// that cannot be circumvented (e.g. #7109, #7153, #7546, #7834, #8109).
// So we now use microtasks everywhere, again.
// A major drawback of this tradeoff is that there are some scenarios
// where microtasks have too high a priority and fire in between supposedly
// sequential events (e.g. #4521, #6690, which have workarounds)
// or even between bubbling of the same event (#6566).
let timerFunc
2
3
4
5
6
7
8
9
10
11
12
13
14
首先我们可以从注释知道next-tick.js 2.5以后,删除了 microTimerFunc 和 macroTimerFunc ,统一使用 micro task 。2.5 版本则是 macrotask 结合 microtask。然而,在重绘之前状态改变时会有小问题(如 #6813)。此外,在事件处理程序中使用 macrotask 会导致一些无法规避的奇怪行为(如#7109,#7153,#7546,#7834,#8109)。所以 2.6 版本现在改用 microtask 了,microtask 在某些情况下也是会有问题的,因为 microtask 优先级比较高,事件会在顺序事件(如#4521,#6690 有变通方法)之间甚至在同一事件的冒泡过程中触发(#6566)。
源码首先是定义一个变量 timerFunc ,保存核心的异步延迟函数,用于异步延迟调用 flushCallbacks 函数。
我们继续往下看,代码如下:
源码目录:src/core/util/next-tick.js
// The nextTick behavior leverages the microtask queue, which can be accessed
// via either native Promise.then or MutationObserver.
// MutationObserver has wider support, however it is seriously bugged in
// UIWebView in iOS >= 9.3.3 when triggered in touch event handlers. It
// completely stops working after triggering a few times... so, if native
// Promise is available, we will use it:
/* istanbul ignore next, $flow-disable-line */
if (typeof Promise !== 'undefined' && isNative(Promise)) {
const p = Promise.resolve()
timerFunc = () => {
p.then(flushCallbacks)
// In problematic UIWebViews, Promise.then doesn't completely break, but
// it can get stuck in a weird state where callbacks are pushed into the
// microtask queue but the queue isn't being flushed, until the browser
// needs to do some other work, e.g. handle a timer. Therefore we can
// "force" the microtask queue to be flushed by adding an empty timer.
if (isIOS) setTimeout(noop)
}
isUsingMicroTask = true
}
// 省略...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
timerFunc 优先使用原生Promise,首先检测当前宿主环境是否支持原生的 Promise,如果支持则优先使用 Promise 注册 microtask,做法很简单,首先定义常量 p 它的值是一个立即 resolve 的 Promise 实例对象,接着将变量 timerFunc 定义为一个函数,这个函数的执行将会把 flushCallbacks 函数注册为 microtask。
接下来是对 iOS 兼容性的处理,从注释我们知道原本 MutationObserver 支持更广,但在iOS >= 9.3.3 的 UIWebView 中,触摸事件处理程序中触发会产生严重错误,即 microtask 没有被刷新。IOS 的 UIWebView,Promise.then 回调被推入microtask 队列但是队列可能不会如期执行。 因此,添加一个空计时器“强制”执行 microtask 队列。
我们继续往下看,代码如下:
源码目录:src/core/util/next-tick.js
// 省略...
else if (!isIE && typeof MutationObserver !== 'undefined' && (
isNative(MutationObserver) ||
// PhantomJS and iOS 7.x
MutationObserver.toString() === '[object MutationObserverConstructor]'
)) {
// Use MutationObserver where native Promise is not available,
// e.g. PhantomJS, iOS7, Android 4.4
// (#6466 MutationObserver is unreliable in IE11)
let counter = 1
const observer = new MutationObserver(flushCallbacks)
const textNode = document.createTextNode(String(counter))
observer.observe(textNode, {
characterData: true
})
timerFunc = () => {
counter = (counter + 1) % 2
textNode.data = String(counter)
}
isUsingMicroTask = true
}
// 省略...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
我们从注释可以知道当原生 Promise 不可用时,timerFunc 使用原生 MutationObserver,如 PhantomJS,iOS7,Android 4.4,issue #6466 MutationObserver 在 IE11 并不可靠,所以这里排除了 IE。
我们在看分析代码, else-if 语句首先判断在非IE的环境下,并且支持原生 MutationObserver的情况下执行,首先定义一个变量 counter 初始值为 1,然后再创建一个 MutationObserver 实例 observer 并以 flushCallbacks 作为回调函数,接着是创建了一个文本节点,作用是通过改变文本节点的内容来触发变动,接下来通过 observe 对目标节点进行观测,接着将变量 timerFunc 定义为一个函数,这个函数的执行将会文本节点的内容,所以,加了这样一个变动监听,用一个文本节点的变动触发监听,等所有 dom 渲染完后,执行函数,达到延迟的效果。
说明:关于 MutationObserver 更多内容请移步 这里 (opens new window) 。
我们继续往下看,代码如下:
源码目录:src/core/util/next-tick.js
// 省略...
else if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
// Fallback to setImmediate.
// Technically it leverages the (macro) task queue,
// but it is still a better choice than setTimeout.
timerFunc = () => {
setImmediate(flushCallbacks)
}
} else {
// Fallback to setTimeout.
timerFunc = () => {
setTimeout(flushCallbacks, 0)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
当原生 Promise 和 MutationObserver 都不支持的时候,判断当前环境是否支持原生 setImmediate ,如果支持 timerFunc 使用原生 setImmediate 。 setImmediate 拥有比 setTimeout 更好的性能,setTimeout 在将回调注册为 (macro)task 之前要不停的做超时检测,而 setImmediate 则不需要,这就是优先选用 setImmediate 的原因。但是 setImmediate 的缺陷也很明显,就是它的兼容性问题,到目前为止只有 IE 浏览器实现了它,所以为了兼容非 IE浏览器我们还需要做兼容处理,此时就使用 setTimeout 。
分析完异步延迟函数的实现,接下来我们看看nextTick 函数的定义,如下:
源码目录:src/core/util/next-tick.js
const callbacks = []
let pending = false
export function nextTick (cb?: Function, ctx?: Object) {
let _resolve
callbacks.push(() => {
if (cb) {
try {
cb.call(ctx)
} catch (e) {
handleError(e, ctx, 'nextTick')
}
} else if (_resolve) {
_resolve(ctx)
}
})
if (!pending) {
pending = true
timerFunc()
}
// $flow-disable-line
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve
})
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
nextTick 函数接收两个参数,第一个参数是一个回调函数,第二个参数指定一个作用域。下面我们逐个分析传递回调函数与不传递回调函数这两种使用场景功能的实现,首先我们来看传递回调函数的情况,那么此时参数 cb 就是回调函数。
nextTick 函数会在 callbacks 数组中添加一个新的函数。注意并不是将 cb 回调函数直接添加到 callbacks 数组中,但这个被添加到 callbacks 数组中的函数的执行会间接调用 cb 回调函数,并且可以看到在调用 cb 函数时使用 .call 方法将函数 cb 的作用域设置为 ctx,也就是 nextTick 函数的第二个参数。所以对于 $nextTick 方法来讲,传递给 $nextTick 方法的回调函数的作用域就是当前组件实例对象,当然了前提是回调函数不能是箭头函数,其实在平时的使用中,回调函数使用箭头函数也没关系,只要你能够达到你的目的即可。另外我们再次强调一遍,此时回调函数并没有被执行,当你调用 $nextTick 方法并传递回调函数时,会使用一个新的函数包裹回调函数并将新函数添加到 callbacks 数组中。
在将回调函数添加到 callbacks 数组之后,会进行一个 if 条件判断,判断变量 pending 的真假,pending 变量是一个标识,它的真假代表回调队列是否处于等待刷新的状态,初始值是 false 代表回调队列为空不需要等待刷新。假如此时在某个地方调用了 $nextTick 方法,那么 if 语句块内的代码将会被执行,在 if 语句块内优先将变量 pending 的值设置为 true,代表着此时回调队列不为空,正在等待刷新。既然等待刷新,那么当然要刷新回调队列啊,怎么刷新呢?这时就用到了我们前面讲过的 timerFunc 函数,我们知道这个函数的作用是将 flushCallbacks 函数分别注册为 microtask 或 (macro)task。但是无论哪种任务类型,它们都将会等待调用栈清空之后才执行。
例如下面案例:
created () {
this.$nextTick(() => { console.log(1) })
this.$nextTick(() => { console.log(2) })
this.$nextTick(() => { console.log(3) })
}
2
3
4
5
上面的代码中我们在 created 钩子中连续调用三次 $nextTick 方法,但只有第一次调用 $nextTick 方法时才会执行 timerFunc 函数将 flushCallbacks 注册为 microtask,但此时 flushCallbacks 函数并不会执行,因为它要等待接下来的两次 $nextTick 方法的调用语句执行完后才会执行,或者准确的说等待调用栈被清空之后才会执行。也就是说当 flushCallbacks 函数执行的时候,callbacks 回调队列中将包含本次事件循环所收集的所有通过 $nextTick 方法注册的回调,而接下来的任务就是在 flushCallbacks 函数内将这些回调全部执行并清空。
接下来我们看看flushCallbacks 函数的定义,如下:
源码目录:src/core/util/next-tick.js
const callbacks = []
let pending = false
function flushCallbacks () {
pending = false
const copies = callbacks.slice(0)
callbacks.length = 0
for (let i = 0; i < copies.length; i++) {
copies[i]()
}
}
2
3
4
5
6
7
8
9
10
11
flushCallbacks 函数首先将变量 pending 重置为 false,接着开始执行回调,但需要注意的是在执行 callbacks 队列中的回调函数时并没有直接遍历 callbacks 数组,而是使用 copies 常量保存一份 callbacks 的复制,然后遍历 copies 数组,并且在遍历 copies 数组之前将 callbacks 数组清空。
例如下面案例:
created () {
this.name = 'test1'
this.$nextTick(() => {
this.name = 'test2'
this.$nextTick(() => { console.log('第二个 $nextTick') })
})
}
2
3
4
5
6
7
上面代码中我们在外层 $nextTick 方法的回调函数中再次调用了 $nextTick 方法,理论上外层 $nextTick 方法的回调函数不应该与内层 $nextTick 方法的回调函数在同一个 microtask 任务中被执行,而是两个不同的 microtask 任务,虽然在结果上看或许没什么差别,但从设计角度就应该这么做。
我们注意上面代码中我们修改了两次 name 属性的值(假设它是响应式数据),首先我们将 name 属性的值修改为字符串 test1,我们前面讲过这会导致依赖于 name 属性的渲染函数观察者被添加到 queue 队列中,这个过程是通过调用 src/core/observer/scheduler.js 文件中的 queueWatcher 函数完成的。同时在 queueWatcher 函数内会使用 nextTick 将 flushSchedulerQueue 添加到 callbacks 数组中,所以此时 callbacks 数组如下:
callbacks = [
flushSchedulerQueue // queue = [renderWatcher]
]
2
3
同时会将 flushCallbacks 函数注册为 microtask,所以此时 microtask 队列如下:
// microtask 队列
[
flushCallbacks
]
2
3
4
接着调用了第一个 $nextTick 方法,$nextTick 方法会将其回调函数添加到 callbacks 数组中,那么此时的 callbacks 数组如下:
callbacks = [
flushSchedulerQueue, // queue = [renderWatcher]
() => {
this.name = 'test2'
this.$nextTick(() => { console.log('第二个 $nextTick') })
}
]
2
3
4
5
6
7
接下来主线程处于空闲状态(调用栈清空),开始执行 microtask 队列中的任务,即执行 flushCallbacks 函数,flushCallbacks 函数会按照顺序执行 callbacks 数组中的函数,首先会执行 flushSchedulerQueue 函数,这个函数会遍历 queue 中的所有观察者并重新求值,完成重新渲染(re-render),在完成渲染之后,本次更新队列已经清空,queue 会被重置为空数组,一切状态还原。接着会执行如下函数:
() => {
this.name = 'test2'
this.$nextTick(() => { console.log('第二个 $nextTick') })
}
2
3
4
这个函数是第一个 $nextTick 方法的回调函数,由于在执行该回调函数之前已经完成了重新渲染,所以该回调函数内的代码是能够访问更新后的DOM的,到目前为止一切都很正常,我们继续往下看,在该回调函数内再次修改了 name 属性的值为字符串 test2,这会再次触发响应,同样的会调用 nextTick 函数将 flushSchedulerQueue 添加到 callbacks 数组中,但是由于在执行 flushCallbacks 函数时优先将 pending 的重置为 false,所以 nextTick 函数会将 flushCallbacks 函数注册为一个新的 microtask,此时 microtask 队列将包含两个 flushCallbacks 函数:
// microtask 队列
[
flushCallbacks, // 第一个 flushCallbacks
flushCallbacks // 第二个 flushCallbacks
]
2
3
4
5
我们的目的达到了,现在有两个 microtask 任务。
而另外除了将变量 pending 的值重置为 false 之外,我们要知道第一个 flushCallbacks 函数遍历的并不是 callbacks 本身,而是它的复制品 copies 数组,并且在第一个 flushCallbacks 函数的一开头就清空了 callbacks 数组本身。所以第二个 flushCallbacks 函数的一切流程与第一个 flushCallbacks 是完全相同。
最后我们再来看一下最后一个 if 语句,当 nextTick 函数没有接收到 cb 参数时,会检测当前宿主环境是否支持 Promise,如果支持则直接返回一个 Promise 实例对象,并且将 resolve 函数赋值给 _resolve 变量,_resolve 变量声明在 nextTick 函数的顶部。
当 flushCallbacks 函数开始执行 callbacks 数组中的函数时,如果没有传递 cb 参数,则直接调用 _resolve 函数,我们知道这个函数就是返回的 Promise 实例对象的 resolve 函数。这样就实现了 Promise 方式的 $nextTick 方法。
说明:microtask 优先级,Promise > MutationObserver > setImmediate > setTimeout 。
# 2.6 $watch
接下来是时候看一下 $watch 方法以及 watch 选项的实现了。实际上无论是 $watch 方法还是 watch 选项,他们的实现都是基于 Watcher 的封装。首先我们来看一下 $watch 方法,它定义如下:
源码目录: src/core/instance/state.js
export function stateMixin (Vue: Class<Component>) {
// 省略...
Vue.prototype.$watch = function (
expOrFn: string | Function, // 监听的属性
cb: any, // 监听的属性对应的回调函数
options?: Object //参数
): Function {
const vm: Component = this
if (isPlainObject(cb)) {
return createWatcher(vm, expOrFn, cb, options)
}
options = options || {}
options.user = true
const watcher = new Watcher(vm, expOrFn, cb, options)
if (options.immediate) {
try {
cb.call(vm, watcher.value)
} catch (error) {
handleError(error, vm, `callback for immediate watcher "${watcher.expression}"`)
}
}
return function unwatchFn () {
watcher.teardown()
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
$watch 方法允许我们观察数据对象的某个属性,当属性变化时执行回调。所以 $watch 方法至少接收两个参数,一个要观察的属性,以及一个回调函数。通过上面的代码我们发现,$watch 方法接收三个参数,除了前面介绍的两个参数之后还接收第三个参数,它是一个选项参数,比如是否立即执行回调或者是否深度观测等。
说明关于 $watch (opens new window) 和 watch选项 (opens new window) 的更多用法可以查看 Vue API 文档
# 2.6.1 纯对象的情况
首先我们假设传递给 $watch 方法的第二个参数是一个纯对象,$watch 首先定义了 vm 常量,它是当前组件实例对象,接着检测传递给 $watch 的第二个参数是否是纯对象,由于我们现在假设参数 cb 是一个纯对象,所以这段 if 语句块内的代码会执行。
当参数 cb 是一个纯对象,则会调用 createWatcher 函数,并将参数透传,注意还多传递给 createWatcher 函数一个参数,即组件实例对象 vm,接下来我们就看看createWatcher 函数也定义,如下:
源码目录: src/core/instance/state.js
function createWatcher (
vm: Component,
expOrFn: string | Function,
handler: any,
options?: Object
) {
if (isPlainObject(handler)) {
options = handler
handler = handler.handler
}
if (typeof handler === 'string') {
handler = vm[handler]
}
return vm.$watch(expOrFn, handler, options)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
createWatcher 函数的作用就是将纯对象形式的参数规范化一下,然后再通过 $watch 方法创建观察者。可以看到 createWatcher 函数的最后一句代码就是通过调用 $watch 函数并将其返回。
createWatcher 函数首先检测参数 handler 是否是纯对象,有的同学可能会问:“在 $watch 方法中已经检测过参数 cb 是否是纯对象了,这里又检测了一次是否多此一举?”,其实这么做并不是多余的,因为 createWatcher 函数除了在 $watch 方法中使用之外,还会用于 watch 选项,而这时就需要对 handler 进行检测。总之如果 handler 是一个纯对象,那么就将变量 handler 的值赋给 options 变量,然后用 handler.handler 的值重写 handler 变量的值。
我们举个例子,如下:
vm.$watch('name', {
handler () {
console.log('name changed')
},
immediate: true
})
2
3
4
5
6
如果你像如上代码那样使用 $watch 方法,那么对于 createWatcher 函数来讲,其 handler 参数为:
handler = {
handler () {
console.log('change')
},
immediate: true
}
2
3
4
5
6
所以如下这段代码:
if (isPlainObject(handler)) {
options = handler
handler = handler.handler
}
2
3
4
等价于:
if (isPlainObject(handler)) {
options = {
handler () {
console.log('change')
},
immediate: true
}
handler = handler () {
console.log('change')
}
}
2
3
4
5
6
7
8
9
10
11
这样就可正常通过 $watch 方法创建观察者了。
我们回到 createWatcher 函数,继续往下看,接下来判断 handler 是否是字符串,这说明 handler 除了可以是一个纯对象还可以是一个字符串,当 handler 是一个字符串时,会读取组件实例对象的 handler 属性的值并用该值重写 handler 的值。然后再通过调用 $watch 方法创建观察者。
我们再来看一个案例,如下:
watch: {
name: 'nameChanged'
},
methods: {
nameChanged () {
console.log('name changed')
}
}
2
3
4
5
6
7
8
上面的代码中我们在 watch 选项中观察了 name 属性,但是我们没有指定回调函数,而是指定了一个字符串 nameChanged,这等价于指定了 methods 选项中同名函数作为回调函数。这就是如上 createWatcher 函数中,判断handler 是否是字符串的目的。
# 2.6.2 函数的情况
我们再回到 $watch, 继续往下看,当第二个参数是一个函数的情况下,首先如果没有传递 options 选项参数,那么会给其一个默认的空对象,接着将 options.user 的值设置为 true,我们前面讲到过这代表该观察者实例是用户创建的,然后就到了关键的一步,即创建 Watcher 实例对象。
再往下是一段 if 语句块,,如果发现 options.immediate 选项为真,那么会执行回调函数,不过此时回调函数的参数只有新值没有旧值。同时取值的方式是通过前面创建的观察者实例对象的 watcher.value 属性。我们知道观察者实例对象的 value 属性,保存着被观察属性的值。
最后 $watch 方法还有一个返回值,$watch 函数返回一个函数,这个函数的执行会解除当前观察者对属性的观察。它的原理是通过调用观察者实例对象的 watcher.teardown 函数实现的。
我们再来看一下 watcher.teardown 函数是如何解除观察者与属性之间的关系的,代码如下:
源码目录:scr/core/observer/watchere.js
/**
* Remove self from all dependencies' subscriber list.
*/
teardown () {
if (this.active) {
// remove self from vm's watcher list
// this is a somewhat expensive operation so we skip it
// if the vm is being destroyed.
if (!this.vm._isBeingDestroyed) {
remove(this.vm._watchers, this)
}
let i = this.deps.length
while (i--) {
this.deps[i].removeSub(this)
}
this.active = false
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
首先检查 this.active 属性是否为真,如果为假则说明该观察者已经不处于激活状态,什么都不需要做,如果为真则会执行 if 语句块内的代码。
首先说明一点,每个组件实例都有一个 vm._isBeingDestroyed 属性,它是一个标识,为真说明该组件实例已经被销毁了,为假说明该组件还没有被销毁,所以以上代码的意思是如果组件没有被销毁,那么将当前观察者实例从组件实例对象的 vm._watchers 数组中移除,我们知道 vm._watchers 数组中包含了该组件所有的观察者实例对象,所以将当前观察者实例对象从 vm._watchers 数组中移除是解除属性与观察者实例对象之间关系的第一步。由于这个参数的性能开销比较大,所以仅在组件没有被销毁的情况下才会执行此操作。
我们知道当一个属性与一个观察者建立联系之后,属性的 Dep 实例对象会收集到该观察者对象,同时观察者对象也会将该 Dep 实例对象收集,这是一个双向的过程,并且一个观察者可以同时观察多个属性,这些属性的 Dep 实例对象都会被收集到该观察者实例对象的 this.deps 数组中,所以解除属性与观察者之间关系的第二步就是将当前观察者实例对象从所有的 Dep 实例对象中移除,这就是 while 循环的作用。
最后会将当前观察者实例对象的 active 属性设置为 false,代表该观察者对象已经处于非激活状态了。
# 2.7 watch 选项
上一章节我们分析了 $watch 的实现,下面我们再来分析 watch 选项的实现, watch 选项的初始化如下:
源码目录:scr/core/instance/state.js
export function initState (vm: Component) {
// 省略...
const opts = vm.$options
if (opts.watch && opts.watch !== nativeWatch) {
initWatch(vm, opts.watch)
}
}
2
3
4
5
6
7
下面我们再来看看 initWatch 函数的定义,代码如下:
源码目录:scr/core/instance/state.js
function initWatch (vm: Component, watch: Object) {
for (const key in watch) {
const handler = watch[key]
if (Array.isArray(handler)) {
for (let i = 0; i < handler.length; i++) {
createWatcher(vm, key, handler[i])
}
} else {
createWatcher(vm, key, handler)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
可以看到 initWatch 函数就是通过对 watch 选项遍历,然后通过 createWatcher 函数创建观察者对象的。
通过 if 条件我们可以发现 handler 常量可以是一个数组,handler 常量的值是 watch[key],也就是说我们在使用 watch 选项时可以通过传递数组来实现创建多个观察者。
例如:
watch: {
name: [
function () {
console.log('name changed 1')
},
function () {
console.log('name changed 2')
}
]
}
2
3
4
5
6
7
8
9
10
# 2.8 深度观测
接下来我们将会讨论深度观测的实现,在这之前我们需要回顾一下数据响应的原理,我们知道响应式数据的关键在于数据的属性是访问器属性,这使得我们能够拦截对该属性的读写操作,从而有机会收集依赖并触发响应。思考如下代码:
watch: {
a () {
console.log('a changed')
}
}
2
3
4
5
这段代码使用 watch 选项观测了数据对象的 a 属性,我们知道 watch 方法内部是通过创建 Watcher 实例对象来实现观测的,在创建 Watcher 实例对象时会读取 a 的值从而触发属性 a 的 get 拦截器函数,最终将依赖收集。但问题是如果属性 a 的值是一个对象,如下:
data () {
return {
a: {
b: 1
}
}
},
watch: {
a () {
console.log('a changed')
}
}
2
3
4
5
6
7
8
9
10
11
12
数据对象 data 的属性 a 是一个对象,当实例化 Watcher 对象并观察属性 a 时,会读取属性 a 的值,这样的确能够触发属性 a 的 get 拦截器函数,但由于没有读取 a.b 属性的值,所以对于 b 来讲是没有收集到任何观察者的。这就是我们常说的浅观察,直接修改属性 a 的值能够触发响应,而修改 a.b 的值是触发不了响应的。
深度观测就是用来解决这个问题的,深度观测的原理很简单,既然属性 a.b 中没有收集到观察者,那么我们就主动读取一下 a.b 的值,这样不就能够触发属性 a.b 的 get 拦截器函数从而收集到观察者了吗,其实 Vue 就是这么做的,只不过你需要将 deep 选项参数设置为 true,主动告诉 Watcher 实例对象你现在需要的是深度观测。我们找到 Watcher 类的 get 方法,如下:
源码目录:scr/core/observer/watchere.js
/**
* Evaluate the getter, and re-collect dependencies.
*/
get () {
pushTarget(this)
let value
const vm = this.vm
try {
value = this.getter.call(vm, vm)
} catch (e) {
if (this.user) {
handleError(e, vm, `getter for watcher "${this.expression}"`)
} else {
throw e
}
} finally {
// "touch" every property so they are all tracked as
// dependencies for deep watching
if (this.deep) {
traverse(value)
}
popTarget()
this.cleanupDeps()
}
return value
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
我们知道 Watcher 类的 get 方法用来求值,在 get 方法内部通过调用 this.getter 函数对被观察的属性求值,并将求得的值赋值给变量 value,同时我们可以看到在 finally 语句块内,如果 this.deep 属性的值为真说明是深度观测,此时会将被观测属性的值 value 作为参数传递给 traverse 函数,其中 traverse 函数的作用就是递归地读取被观察属性的所有子属性的值,这样被观察属性的所有子属性都将会收集到观察者,从而达到深度观测的目的。
接下来我们看看 traverse 函数的定义,如下:
源码目录: src/core/observer/traverse.js
const seenObjects = new Set()
/**
* Recursively traverse an object to evoke all converted
* getters, so that every nested property inside the object
* is collected as a "deep" dependency.
*/
export function traverse (val: any) {
_traverse(val, seenObjects)
seenObjects.clear()
}
2
3
4
5
6
7
8
9
10
traverse 函数将接收被观察属性的值作为参数,拿到这个参数后在 traverse 函数内部会调用 _traverse 函数完成递归遍历。
接下来我们再来看看 _traverse 函数的定义,如下:
源码目录: src/core/observer/traverse.js
function _traverse (val: any, seen: SimpleSet) {
let i, keys
const isA = Array.isArray(val)
if ((!isA && !isObject(val)) || Object.isFrozen(val) || val instanceof VNode) {
return
}
if (val.__ob__) {
const depId = val.__ob__.dep.id
if (seen.has(depId)) {
return
}
seen.add(depId)
}
if (isA) { // 数组情况
i = val.length
while (i--) _traverse(val[i], seen)
} else { // 对象情况
keys = Object.keys(val)
i = keys.length
while (i--) _traverse(val[keys[i]], seen)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
_traverse 函数接收两个参数,第一个参数是被观察属性的值,第二个参数是一个 Set 数据结构的实例,可以看到在 traverse 函数中调用 _traverse 函数时传递的第二个参数 seenObjects 就是一个 Set 数据结构的实例。
在 _traverse 函数的开头声明了两个变量,分别是 i 和 keys,这两个变量在后面会使用到,接着检查参数 val 是不是数组,并将检查结果存储在常量 isA 中。
接着是对参数 val(被观察属性的值) 的检查,我们知道既然是深度观测,所以被观察属性的值要么是一个对象要么是一个数组,并且该值不能是冻结的,同时也不应该是 VNode 实例(这是 Vue 单独做的限制)。只有当被观察属性的值满足这些条件时,才会对其进行深度观测,只要有一项不满足 _traverse 就会 return 结束执行。
接下来的这个 if 语句块的作用是解决循环引用导致死循环的问题,为了更好地说明问题我们举个例子,如下:
const obj1 = {}
const obj2 = {}
obj1.data = obj2
obj2.data = obj1
2
3
4
5
上面代码中我们定义了两个对象,分别是 obj1 和 obj2,并且 obj1.data 属性引用了 obj2,而 obj2.data 属性引用了 obj1,这是一个典型的循环引用,假如我们使用 obj1 或 obj2 这两个对象中的任意一个对象出现在 Vue 的响应式数据中,如果不做防循环引用的处理,将会导致死循环。
为了避免这种情况的发生,我们可以使用一个变量来存储那些已经被遍历过的对象,当再次遍历该对象时程序会发现该对象已经被遍历过了,这时会跳过遍历,从而避免死循环。if 语句块,用来判断 val.__ob__ 是否有值,我们知道如果一个响应式数据是对象或数组,那么它会包含一个叫做 __ob__ 的属性,这时我们读取 val.__ob__.dep.id 作为一个唯一的 ID 值,并将它放到 seenObjects 中:seen.add(depId),这样即使 val 是一个拥有循环引用的对象,当下一次遇到该对象时,我们能够发现该对象已经遍历过了:seen.has(depId),这样函数直接 return 即可。这就是避免循环引用造成的死循环的解决方案。
接着将检测被观察属性的值是数组还是对象,无论是数组还是对象都会通过 while 循环对其进行遍历,并递归调用 _traverse 函数,这段代码的关键在于递归调用 _traverse 函数时所传递的第一个参数:val[i] 和 val[keys[i]]。这两个参数实际上是在读取子属性的值,这将触发子属性的 get 拦截器函数,保证子属性能够收集到观察者,仅此而已。
# 2.9 计算属性
通过前面几章的分析我们知道计算属性,它本质上就是一个惰性求值的观察者。那么下面这一小节我们来分析一下计算属性的实现,计算属性的初始化代码如下:
源码目录:scr/core/instance/state.js
export function initState (vm: Component) {
// 省略...
const opts = vm.$options
if (opts.computed) initComputed(vm, opts.computed)
// 省略...
}
2
3
4
5
6
这句代码首先检查开发者是否传递了 computed 选项,只有传递了该选项的情况下才会调用 initComputed 函数进行初始化。
下面我们再来看看 initComputed 函数的定义,由于这块代码比较多,我们依旧按照之前的分析方式,分段来讲解,首先看一下如下代码:
源码目录:scr/core/instance/state.js
function initComputed (vm: Component, computed: Object) {
// 省略...
}
2
3
initComputed 函数接收两个参数,第一个参数是组件对象实例,第二个参数是对应的选项。
我们继续往下看,代码如下:
源码目录:scr/core/instance/state.js
function initComputed (vm: Component, computed: Object) {
// $flow-disable-line
const watchers = vm._computedWatchers = Object.create(null)
// computed properties are just getters during SSR
const isSSR = isServerRendering()
// 省略...
}
2
3
4
5
6
7
initComputed 函数首先定义了两个常量,其中 watchers 常量与组件实例的 vm._computedWatchers 属性拥有相同的引用,且初始值都是通过 Object.create(null) 创建的空对象,isSSR 常量是用来判断是否是服务端渲染的布尔值。
我们继续往下看,代码如下:
源码目录:scr/core/instance/state.js
function initComputed (vm: Component, computed: Object) {
// 省略...
for (const key in computed) {
// 省略...
}
}
2
3
4
5
6
接着开启一个 for...in 循环,这个 for...in 循环用来遍历 computed 选项对象。
我们继续往下看,代码如下:
源码目录:scr/core/instance/state.js
function initComputed (vm: Component, computed: Object) {
// 省略...
for (const key in computed) {
const userDef = computed[key]
const getter = typeof userDef === 'function' ? userDef : userDef.get
if (process.env.NODE_ENV !== 'production' && getter == null) {
warn(
`Getter is missing for computed property "${key}".`,
vm
)
}
// 省略...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
定义了 userDef 常量,它的值是计算属性对象中相应的属性值,我们知道计算属性有两种写法,计算属性可以是一个函数,如下案例:
computed: {
fullName () {
return this.firstName + this.lastName
}
}
2
3
4
5
如果你使用上面的写法,那么 userDef 的值就是一个函数:
userDef = fullName () {
return this.firstName + this.lastName
}
2
3
另外计算属性也可以写成对象,如下案例:
computed: {
fullName: {
get: function () {
return this.firstName + this.lastName
},
set: function (v) {
const full = v.split(' ')
this.firstName = full[0]
this.lastName = full[1]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
如果你使用如上这种写法,那么 userDef 常量的值就是一个对象:
userDef = {
get: function () {
return this.firstName + this.lastName
},
set: function (v) {
const full = v.split(' ')
this.firstName = full[0]
this.lastName = full[1]
}
}
2
3
4
5
6
7
8
9
10
在 userDef 常量的下面定义了 getter 常量,它的值是根据 userDef 常量的值决定的,如果计算属性使用函数的写法,那么 getter 常量的值就是 userDef 本身,即函数。如果计算属性使用的是对象写法,那么 getter 的值将会是 userDef.get 函数。总之 getter 常量总会是一个函数。接着是在非生产环境下如果发现 getter 不存在,则直接打印警告信息,提示你计算属性没有对应的 getter。
我们继续往下看,代码如下:
源码目录:scr/core/instance/state.js
const computedWatcherOptions = { lazy: true }
function initComputed (vm: Component, computed: Object) {
// 省略...
for (const key in computed) {
// 省略...
if (!isSSR) {
// create internal watcher for the computed property.
watchers[key] = new Watcher(
vm, // vm vode
getter || noop, // 函数
noop, // 回调函数
computedWatcherOptions //参数 lazy = true
)
}
// 省略...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
上面这段代码只有在非服务端渲染时才会执行 if 语句块内的代码,因为服务端渲染中计算属性的实现本质上和使用 methods 选项差不多。这里我们着重讲解非服务端渲染的实现,这时 if 语句块内的代码会被执行,可以看到在 if 语句块内创建了一个观察者实例对象,我们称之为 计算属性的观察者,同时会把计算属性的观察者添加到 watchers 常量对象中,键值是对应计算属性的名字,注意由于 watchers 常量与 vm._computedWatchers 属性具有相同的引用,所以对 watchers 常量的修改相当于对 vm._computedWatchers 属性的修改,现在你应该知道了,vm._computedWatchers 对象是用来存储计算属性观察者的。
另外有几点需要注意,首先创建计算属性观察者时所传递的第二个参数是 getter 函数,也就是说计算属性观察者的求值对象是 getter 函数。传递的第四个参数是 computedWatcherOptions 常量,它是一个对象,定义在 initComputed 函数的上方。
我们知道传递给 Watcher 类的第四个参数是观察者的选项参数,选项参数对象可以包含如 deep、sync 等选项,当然了其中也包括 lazy 选项,通过如上这句代码可知在创建计算属性观察者对象时 lazy 选项为 true,它的作用就是用来标识一个观察者对象是计算属性的观察者,计算属性的观察者与非计算属性的观察者的行为是不一样的。
我们继续往下看,代码如下:
源码目录:scr/core/instance/state.js
const computedWatcherOptions = { lazy: true }
function initComputed (vm: Component, computed: Object) {
// 省略...
for (const key in computed) {
// 省略...
// component-defined computed properties are already defined on the
// component prototype. We only need to define computed properties defined
// at instantiation here.
if (!(key in vm)) {
defineComputed(vm, key, userDef)
} else if (process.env.NODE_ENV !== 'production') {
if (key in vm.$data) {
warn(`The computed property "${key}" is already defined in data.`, vm)
} else if (vm.$options.props && key in vm.$options.props) {
warn(`The computed property "${key}" is already defined as a prop.`, vm)
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这段代码首先检查计算属性的名字是否已经存在于组件实例对象中,我们知道在初始化计算属性之前已经初始化了 props、methods 和 data 选项,并且这些选项数据都会定义在组件实例对象上,由于计算属性也需要定义在组件实例对象上,所以需要使用计算属性的名字检查组件实例对象上是否已经有了同名的定义,如果该名字已经定义在组件实例对象上,那么有可能是 data 数据或 props 数据或 methods 数据之一,对于 data 和 props 来讲他们是不允许被 computed 选项中的同名属性覆盖的,所以在非生产环境中还要检查计算属性中是否存在与 data 和 props 选项同名的属性,如果有则会打印警告信息。如果没有则调用 defineComputed 定义计算属性。
下面我们再来看看 defineComputed 函数的定义,代码如下:
源码目录:scr/core/instance/state.js
export function defineComputed (
target: any,
key: string,
userDef: Object | Function
) {
const shouldCache = !isServerRendering()
if (typeof userDef === 'function') {
sharedPropertyDefinition.get = shouldCache
? createComputedGetter(key)
: createGetterInvoker(userDef)
sharedPropertyDefinition.set = noop
} else {
sharedPropertyDefinition.get = userDef.get
? shouldCache && userDef.cache !== false
? createComputedGetter(key)
: createGetterInvoker(userDef.get)
: noop
sharedPropertyDefinition.set = userDef.set || noop
}
if (process.env.NODE_ENV !== 'production' &&
sharedPropertyDefinition.set === noop) {
sharedPropertyDefinition.set = function () {
warn(
`Computed property "${key}" was assigned to but it has no setter.`,
this
)
}
}
Object.defineProperty(target, key, sharedPropertyDefinition)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
在 defineComputed 函数开头定义了 shouldCache 常量,它的值与 initComputed 函数中定义的 isSSR 常量的值是取反的关系,也是一个布尔值,用来标识是否应该缓存值,也就是说只有在非服务端渲染的情况下计算属性才会缓存值。
接着是一个 if...else 语句块,作用是为 sharedPropertyDefinition.get 和 sharedPropertyDefinition.set 赋予合适的值。首先检查 userDef 是否是函数,如果是函数则执行 if 语句块内的代码,如果不是函数则说明 userDef 是对象,此时会执行 else 分支的代码。假如 userDef 是函数,在 if 语句块内首先会使用三元运算符检查 shouldCache 是否为真,如果为真说明不是服务端渲染,此时会调用 createComputedGetter 函数并将其返回值作为 sharedPropertyDefinition.get 的值。如果 shouldCache 为假说明是服务端渲染,由于服务端渲染不需要缓存值,所以会调用 createGetterInvoker 函数并将其返回值作为 sharedPropertyDefinition.get 的值。另外由于 userDef 是函数,这说明该计算属性并没有指定 set 拦截器函数,所以直接将其设置为空函数 noop:sharedPropertyDefinition.set = noop。
如果代码走到了 else 分支,那说明 userDef 是一个对象,如果 userDef.get 存在并且是在非服务端渲染的环境下,同时没有指定选项 userDef.cache 为假,则此时会调用 createComputedGetter 函数并将其返回值作为 sharedPropertyDefinition.get 的值,否则 sharedPropertyDefinition.get 的值为 createGetterInvoker 函数执行的返回值。同样的如果 userDef.set 函数存在,则使用 userDef.set 函数作为 sharedPropertyDefinition.set 的值,否则使用空函数 noop 作为其值。
接着是一个 if 条件语句块,在非生产环境下如果发现 sharedPropertyDefinition.set 的值是一个空函数,那么说明开发者并没有为计算属性定义相应的 set 拦截器函数,这时会重写 sharedPropertyDefinition.set 函数,这样当你在代码中尝试修改一个没有指定 set 拦截器函数的计算属性的值时,就会得到一个警告信息。
最后通过 Object.defineProperty 函数在组件实例对象上定义与计算属性同名的组件实例属性,而且是一个访问器属性,属性的配置参数是 sharedPropertyDefinition 对象。
下面我们再来看看 sharedPropertyDefinition 对象的定义,代码如下:
源码目录:scr/core/instance/state.js
/**
* configurable:当且仅当该属性的 configurable 键值为 true 时,该属性的描述符才能够被改变,同时该属性也能从对应的对象上被删除。默认为 false
* enumerable:当且仅当该属性的 enumerable 键值为 true 时,该属性才会出现在对象的枚举属性中。默认为 false
* 数据描述符:
* value:该属性对应的值。可以是任何有效的 JavaScript 值(数值,对象,函数等)。默认为 undefined
* writable:当且仅当该属性的 writable 键值为 true 时,属性的值,也就是上面的 value,才能被赋值运算符改变。默认为 false
* 存取描述符:
* get:属性的 getter 函数,如果没有 getter,则为 undefined。当访问该属性时,会调用此函数。执行时不传入任何参数,但是会传入 this 对象(由于继承关系,这里的this并不一定是定义该属性的对象)。该函数的返回值会被用作属性的值。默认为 undefined
* set:属性的 setter 函数,如果没有 setter,则为 undefined。当属性值被修改时,会调用此函数。该方法接受一个参数(也就是被赋予的新值),会传入赋值时的 this 对象。默认为 undefined
*/
const sharedPropertyDefinition = {
enumerable: true,
configurable: true,
get: noop,
set: noop
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
总之,无论 userDef 是函数还是对象,在非服务端渲染的情况下,配置对象 sharedPropertyDefinition 最终将变成如下这样:
sharedPropertyDefinition = {
enumerable: true,
configurable: true,
get: createComputedGetter(key),
set: userDef.set // 或 noop
}
2
3
4
5
6
举个例子,假如我们像如下这样定义计算属性:
computed: {
fullName () {
return this.firstName + this.lastName
}
}
2
3
4
5
那么定义 fullName 访问器属性时的配置对象为:
sharedPropertyDefinition = {
enumerable: true,
configurable: true,
get: createComputedGetter(key),
set: noop // 没有指定 userDef.set 所以是空函数
}
2
3
4
5
6
下面我们再来看看 createComputedGetter 方法的定义,代码如下:
源码目录:scr/core/instance/state.js
function createComputedGetter (key) {
return function computedGetter () {
const watcher = this._computedWatchers && this._computedWatchers[key]
if (watcher) {
if (watcher.dirty) {
watcher.evaluate()
}
if (Dep.target) {
watcher.depend()
}
return watcher.value
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
可以看到 createComputedGetter 函数只是返回一个叫做 computedGetter 的函数,并没有做任何其他事情。也就是说计算属性真正的 get 拦截器函数就是 computedGetter 函数,如下:
sharedPropertyDefinition = {
enumerable: true,
configurable: true,
get: function computedGetter () {
const watcher = this._computedWatchers && this._computedWatchers[key]
if (watcher) {
if (watcher.dirty) {
watcher.evaluate()
}
if (Dep.target) {
watcher.depend()
}
return watcher.value
}
},
set: noop // 没有指定 userDef.set 所以是空函数
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
分析 createComputedGetter 返回函数具体实现之前我们举个例子,代码如下:
data () {
return {
firstName: 'Bill',
lastName: 'Gates'
}
},
computed: {
fullName () {
return this.firstName + this.lastName
}
}
2
3
4
5
6
7
8
9
10
11
如上代码中,我们定义了本地数据 data,它拥有一个响应式的属性 firstName 和 lastName,我们还定义了计算属性 fullName,它的值将依据 firstName 和 lastName 的值来计算求得。另外我们假设有如下模板:
<div>{{ fullName }}</div>
模板中我们使用到了计算属性,我们知道模板会被编译成渲染函数,渲染函数的执行将触发计算属性 fullName 的 get 拦截器函数,那么 fullName 的拦截器函数是什么呢?就是我们前面分析的 sharedPropertyDefinition.get 函数,我们知道在非服务端渲染的情况下,这个函数为:
sharedPropertyDefinition.get = function computedGetter () {
const watcher = this._computedWatchers && this._computedWatchers[key]
if (watcher) {
if (watcher.dirty) {
watcher.evaluate()
}
if (Dep.target) {
watcher.depend()
}
return watcher.value
}
}
2
3
4
5
6
7
8
9
10
11
12
也就是说当 fullName 属性被读取时,computedGetter 函数将会执行,在 computedGetter 函数内部,首先定义了 watcher 常量,它的值为计算属性 fullName 的观察者对象,紧接着如果该观察者对象存在,则会分别执行观察者对象的 depend 方法和 evaluate 方法,最后返回计算属性的值。这里需要注意的是 watcher.dirty 值是 true,因为我们再 initComputed 函数中实例化 watcher 时第四个参数是 computedWatcherOptions 及 { lazy: true } ,而在 Watcher 构造函数的 constructor 中有这样的一句 this.dirty = this.lazy ,所以在此处的 watcher.dirty 值是 true。
下面我们再来看看 Watcher 类的 evaluate 方法的定义,代码如下:
源码目录:scr/core/observer/watcher.js
/**
* Evaluate the value of the watcher.
* This only gets called for lazy watchers.
*/
evaluate () {
this.value = this.get()
this.dirty = false
}
2
3
4
5
6
7
8
我们知道计算属性的观察者是惰性求值,所以在创建计算属性观察者时除了 watcher.lazy 属性为 true 之外,watcher.dirty 属性的值也为 true,代表着当前观察者对象没有被求值,而 evaluate 方法的作用就是用来手动求值的。可以看到在 evaluate 方法内部调用观察者对象的 this.get 方法求值,同时将this.dirty 属性重置为 false。
我们在前面讲过了,在创建计算属性观察者对象时传递给 Watcher 类的第二个参数为 getter 常量,它的值就是开发者在定义计算属性时的函数(或 userDef.get),所以在 evaluate 方法中求值的那句代码最终所执行的求值函数就是用户定义的计算属性的 get 函数。
在我们当前案例中,计算属性 fullName 依赖了数据对象的 firstName 和 lastName 属性,那么属性 firstName 和 lastName 将收集计算属性 fullName 的 计算属性观察者对象,而 计算属性观察者对象 将收集 渲染函数观察者对象。
假如此时我们修改响应式属性 firstName 和 lastName 的值,那么将触发属性 firstName 和 lastName 所收集的所有依赖,这其中包括计算属性的观察者。我们知道触发某个响应式属性的依赖实际上就是执行该属性所收集到的所有观察者的 update 方法,现在我们就找到 Watcher 类的 update 方法。
下面我们再来看看 Watcher 类的 update 方法的定义,代码如下:
源码目录:scr/core/observer/watcher.js
/**
* Subscriber interface.
* Will be called when a dependency changes.
*/
update () {
/* istanbul ignore else */
if (this.lazy) {
this.dirty = true
} else if (this.sync) {
this.run()
} else {
queueWatcher(this)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
函数会重新计算,然后对比新旧值,如果变化了则执行回调函数,那么这里这个回调函数是 this.dep.notify(),在我们这个场景下就是触发了渲染 watcher 重新渲染。
通过以上的分析,我们知道计算属性本质上就是一个 computed watcher,也了解了它的创建过程和被访问触发 getter 以及依赖更新的过程,其实这是最新的计算属性的实现,之所以这么设计是因为 Vue 想确保不仅仅是计算属性依赖的值发生变化,而是当计算属性最终计算的值发生变花才会触发渲染 watcher 重新渲染,本质上是一种优化。
下面我们再来看看 Watcher 类的 depend 方法的定义,代码如下:
源码目录:scr/core/instance/state.js
/**
* Depend on all deps collected by this watcher.
*/
depend () {
// 获取计算watcher的所有deps
let i = this.deps.length
while (i--) {
// 为该deps增加渲染watcher
this.deps[i].depend()
}
}
2
3
4
5
6
7
8
9
10
11
depend 方法的内容很简单,遍历 this.deps,执行每一个 this.dep.depend 方法。这里我们首先要知道 this.deps 属性是什么,实际上计算属性的观察者与其他观察者对象不同,不同之处首先会体现在创建观察者实例对象的时候,当创建计算属性观察者对象时,由于第四个选项参数中 options.lazy 为真,所以计算属性观察者对象的 this.lazy 属性的值也会为真,所以对于计算属性的观察者来讲,这说明计算属性的观察者是一个惰性求值的观察者。
下面我们再来看看 Dep 类的 depend 方法的定义,代码如下:
源码目录:scr/core/instance/dep.js
depend () {
// 把当前Dep对象实例添加到当前正在计算的Watcher的依赖中
if (Dep.target) {
Dep.target.addDep(this)
}
}
2
3
4
5
6
此时我们已经知道了 this.dep[i] 属性是一个 Dep 实例对象,所以 this.dep[i].depend() 这句代码的作用就是用来收集依赖。那么它收集到的东西是什么呢?这就要看 Dep.target 属性的值是什么了,我们回想一下整个过程:首先渲染函数的执行会读取计算属性 fullName 的值,从而触发计算属性 fullName 的 get 拦截器函数,最终调用了 dep.depend() 方法收集依赖。这个过程中的关键一步就是渲染函数的执行,我们知道在渲染函数执行之前 Dep.target 的值必然是 渲染函数的观察者对象。
# 2.10 同步执行
通常情况下当数据状态发生改变时,所有 Watcher 都为异步执行,这么做的目的是出于对性能的考虑。但在某些场景下我们仍需要同步执行的观察者,我们可以使用 sync 选项定义同步执行的观察者,如下:
new Vue({
watch: {
someWatch: {
handler () {/* ... */},
sync: true
}
}
})
2
3
4
5
6
7
8
如上代码所示,我们在定义一个观察者时使用 sync 选项,并将其设置为 true,此时当数据状态发生变化时该观察者将以同步的方式执行。这么做当然没有问题,因为我们仅仅定义了一个观察者而已。
在我们之前对 setter 的分析过程知道,当响应式数据发送变化后,触发了 watcher.update(),只是把这个 watcher 推送到一个队列中,在 nextTick 后才会真正执行 watcher 的回调函数。而一旦我们设置了 sync,就可以在当前 Tick 中同步执行 watcher 的回调函数。
源码目录:src/core/observer/watcher.js
/**
* Subscriber interface.
* Will be called when a dependency changes.
*/
update () {
/* istanbul ignore else */
if (this.lazy) {
this.dirty = true
} else if (this.sync) {
this.run()
} else {
queueWatcher(this)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
只有当我们需要 watch 的值的变化到执行 watcher 的回调函数是一个同步过程的时候才会去设置该属性为 true。
# 2.11 Watcher 类型
depp watcheruser watchercomputed watchersync watcher
# 3. 总结
计算属性本质上是 computed watcher ,而侦听属性本质上是 user watcher 。就应用场景而言,计算属性适合用在模板渲染中,某个值是依赖了其它的响应式对象甚至是计算属性计算而来;而侦听属性适用于观测某个值的变化去完成一段复杂的业务逻辑。
watcher 的 4 个 options ,通常我们会在创建user watcher 的时候配置 deep 和 sync ,可以根据不同的场景做相应的配置。